
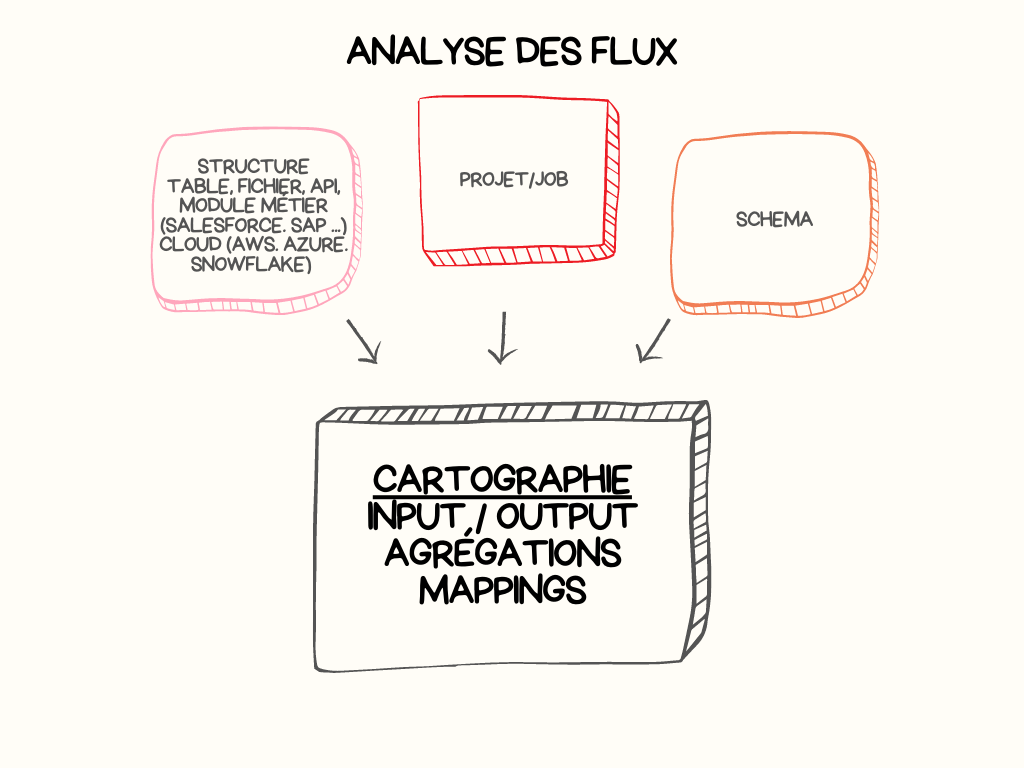
L’analyse des flux permet de réaliser des recherches sur la structure des données. La recherche est orientée sur l’utilisation des champs dans les composants, les jobs et les projets.
L’analyse est composé de 3 modules
- Input/output
Ce module permet de réaliser des analyses sur les entrées et les sorties des jobs. Il est focalisé sur les structures qui permettent d’interroger les données depuis une source et les structures qui permettent d’injecter les données vers une cible.
- Agrégation
Ce module permet de réaliser des analyses sur l’utilisation des champs au niveau des agrégations réalisées au niveau des composants tAggregateRow et tAggregateSortedRow.
- Mapping
Ce module permet de réaliser des analyses sur l’utilisation des champs au niveau des composants tMap.
Les structures qu’on peut trouver se trouve dans le tableau (annexe 2)
Les requêtes SQL sont également analysées pour permettre de récupérer les tables et les champs utilisés au niveau des composants tDBRow (Update, Insert, delete, merge) et tDBInput (Select).
| Composant | Sens | Element |
| tDbRow | Output | TABLE_UPDATE |
| tDBRow | Output | TABLE_INSERT |
| tDBRow | Output | TABLE_MERGE |
| tDBRow | Output | TABLE_DELETE |
| tDBRow | INput | TABLE |
Mode de recherche
- Recherche par Projet / Job / Préfix de job

La recherche par projet / Job / préfix de Job permet de réduire le champ de recherche pour pouvoir se focaliser sur un projet ou un ensemble de projet, sur un job ou un ensemble de job ou bien en appliquant un préfix de job.
- Input / Output
La recherche peut se réaliser en combinant le champ, la structure (Elements), le nom de la structure (Value elements).
- Aggregation
La recherche peut se réaliser en combinant le nom du champ et le nom de la fonction utilisé
La liste des fonction utilisés sont :
- GROUPBY
- min
- max
- sum
- avg
- first
- last
- Mapping
La recherche se réalise au niveau des champs en entrée ou des champs en sortie du tMap.